Augmented Audio
Research
As of today, augmented audio experiments deliver pre-recorded audio snippets based on different parameters. Their non-linearity is restricted by the exponential nature of pre-production. To break up these borders, I propose using real-time dynamic composition to reach total flexibility.
My research will focus on using them in different contexts and drafts to demonstrate their potential use. It will range from hybrid formats, synthetic voice extension up to fully generated audio pieces.
Vision
I believe in a future, where linear audio has evolved to its next step. Constantly adapting to the users' environment, for greater relevance and immersion. Personalized news, dynamic in-depth podcasts, real-time adapting art pieces, heresque voices in our heads, all web-based, accompanying us wherever we go — true situation based audio.
This is not the death of classic narrative, but its rebirth with contemporary possibilities of audio playback and generation.
by Vinzenz Aubry
Projects
Currently looking for funding
- Translation budget for social score
- Development support for Gencaster
Please contact, if you can help with any of it.
2023 - Today Gencaster

A non-linear audio streaming framework for real-time radiophonic experiences and live music. Check it out here.
2022/2023 Drifter (DE)

© Mathias Trumminger
In production.
2021 Dear Joachim (Multilang)

© vog.photo
Web-based digital condolence and contemplative spatial audio installation reflecting on the personal impact late media artist and designer Joachim Sauter had on many of us. Speech-to-text and keyword matching attempt to chain the thoughts in correlated narrative, reflecting the encounters between colleagues and students of different generations, who came together to remember Joachim, and realised that similar strands transcended the different years.
You are invited to leave a short voice contemplation that will be part of an acoustic installation at Ars Electronica festival in Linz; a place, event and a community very close to Joachim from its inception: dearjoachim.digital.udk-berlin.de.
Credtits: Hannes Hoelzl (IT), Dirk Erdmann (DE), Vinzenz Aubry (DE/FR), Ólafur Arnalds (IS), Robert Schnüll (DE), Alberto de Campo (AT), Jussi Ängeslevä (FI), Andi Ruckel (DE), Bruno Gola (BR)
2020 - 2021 Future Voices (Multilang) by S4NTP
»Future Voices/Zukunftsmusik« invites people from all over the world to give voice to what they expect, hope, or fear for the future. Their contributions flow into a generative sound stream composed from these individual »Future Voices«; voices that would otherwise remain unheard within an attention economy that favours loudness, provocation, and conspiracy theories.
This project was commissioned by Deutschlandfunk Kultur / Klangkunst, ORF Kunstradio, and CTM Festival. It is created and will be expanded by The Society For Non-Trivial Pursuits (S4NTP), which is affiliated to the Class for Generative Arts / Computational Art at Berlin Arts University UdK.
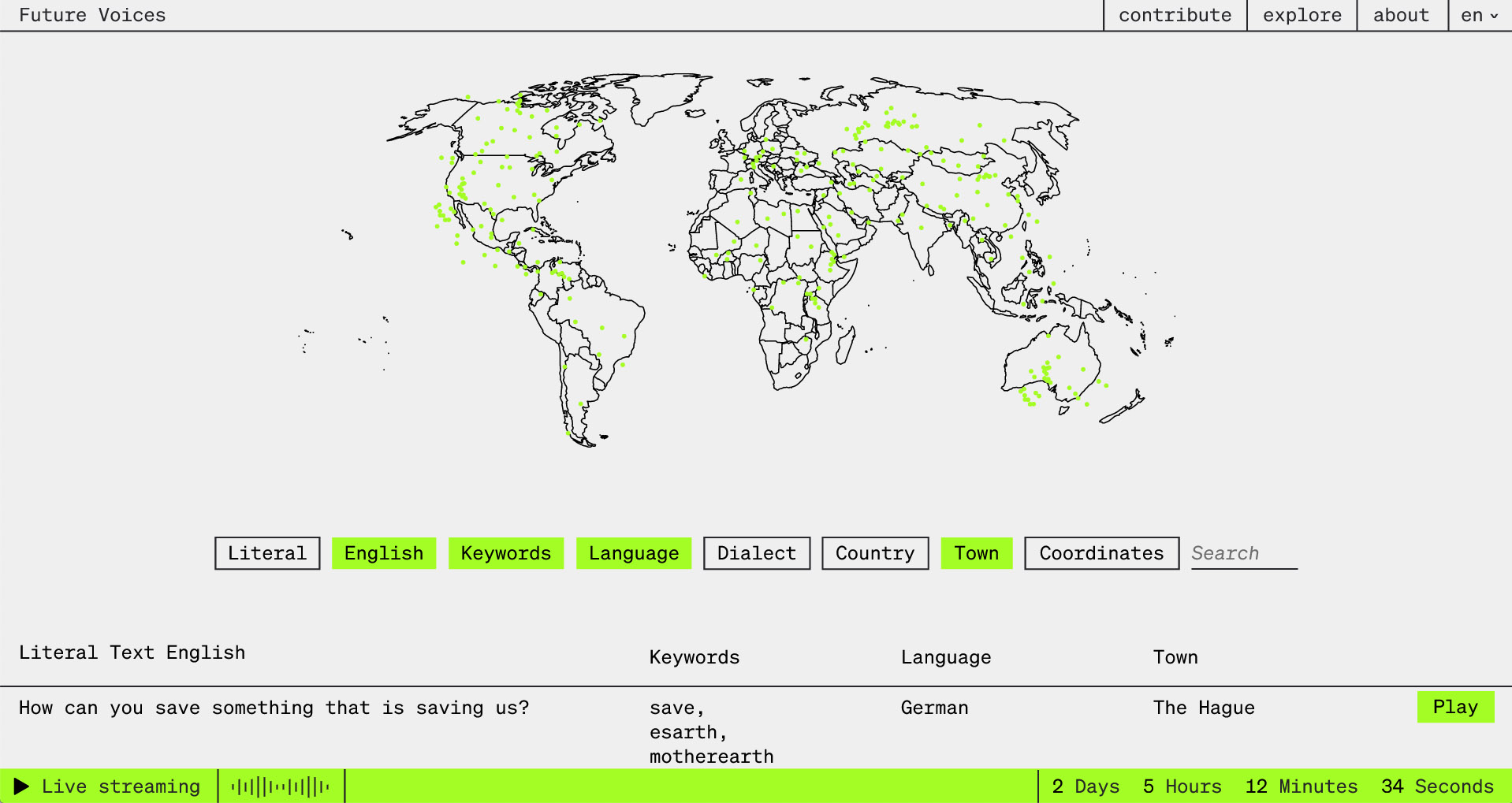
Explore at: futurevoices.radio.
Tags:
- participatory art
- radio art
2020 __FM (Multilang)
A personal auditive content curator. During the current lockdown period, the government’s main concern is the physical protection of all citizens. However, as the period extends, an increasing psychological burden appears due to media over-confrontation with Covid-19.

As a frequent radio listener, I was trying to find a solution to avoid the topic without cutting myself off. Therefore, I added a curation layer on the consumer’s side: a personal audio content curator.
It’s a real-time pipeline which checks an online radio stream of choice via speech recognition for predefined words. It then replaces those with another custom sound/word. An analog FM radio signal is then transmitted throughout my apartment, thus overwriting my kitchen radio with a cleaned, self-protecting audio stream.
This way I can go back to listening to early morning radio, cleaned from stress-inducing influences.

video documentation - running code - github
2019 Social Score - Nothing to Hide (DE)

Social score negotiates the potential introduction of a social scoring system in Germany. It is a live generated, speech synthesised and GPS based audiobook directly playable in any smartphone browser.
During a free walk, the listeners experience the advantages and disadvantages of such a system with the fictitious AI « AVA ». The augmented audio piece is synthesised and composed live and individually by analysing GPS position data and comparing them with databases of location and object data.
socialscore.eu - video documentation - trailer

Realized for and with sansho.studio and Ralph Tharayil.
- Nominated for Online Grimme Award and Prix Europa
- Won section digital at International Documentary Film Festival Munich
Status
O searching for EN / FR translation funding